You never want to come in to work to find that one of your critical SQL Server databases is corrupt but that’s exactly what happened today due to a SAN issue. I’ve got a fair amount of SQL Server experience but not so much so that a failed SQL Server corruption check doesn’t instinctively cause me to wonder out loud how up to date my CV is 😉
That said we did manage to repair the corruption with no downtime and no data loss so I thought I’d do a quick blog to describe what I did to resolve the issue in case it helps anyone who has a similar issue.
Its important to understand that there are a huge variety of corruption scenarios that can occur in the real world and the lessons here may well not apply to you. Our DB failed in a very specific way that lent itself to a relatively quick repair with no downtime. You may be able to take some of the ideas here and run with them though so I thought it worth a share.
What did SQL Server think was wrong?
We picked up on the problem when one of our custom maintenance jobs emailed me the results of a failed DBCC CHECKDB command. These corruption checks are crucial as they tell you about problems whilst you still have enough backups in rotation to be able to do something about them. I’ve actually gone as far as running them nightly using some hand crafted scripts that will email step by step guidance to the IT team on how to handle the problem in case I’m on holiday. If you aren’t doing frequent DBCC CHECKDBs, you really need to start now.
The first thing we want to do is find out what SQL Server thinks is wrong. The key thing to do here is not panic. The SharePoint system in question was clattering a long quite happily at this point so there is plenty of time to gather diagnostics.
The first thing we want to do is to run a full CHECKDB. This will give us SQL Server’s assessment of what’s wrong and would likely be the first thing MS would ask for if you called them:
DBCC CHECKDB ('<database.') with no_infomsgs
This gave us the following output, giving us our initial handle on how severe the problem was (apologies for the formatting):
Msg 8961, Level 16, State 1, Line 1
Table error: Object ID 373576369, index ID 1, partition ID 72057594081902592, alloc unit ID 72057594040549376 (type LOB data). The off-row data node at page (1:373408), slot 0, text ID 333774848 does not match its reference from page (1:46982), slot 0.
Msg 8961, Level 16, State 1, Line 1
Table error: Object ID 373576369, index ID 1, partition ID 72057594081902592, alloc unit ID 72057594040549376 (type LOB data). The off-row data node at page (1:373409), slot 0, text ID 333774848 does not match its reference from page (1:46982), slot 0.
Msg 8961, Level 16, State 1, Line 1
Table error: Object ID 373576369, index ID 1, partition ID 72057594081902592, alloc unit ID 72057594040549376 (type LOB data). The off-row data node at page (1:373410), slot 0, text ID 333774848 does not match its reference from page (1:46982), slot 0.
Msg 8961, Level 16, State 1, Line 1
Table error: Object ID 373576369, index ID 1, partition ID 72057594081902592, alloc unit ID 72057594040549376 (type LOB data). The off-row data node at page (1:373411), slot 0, text ID 333774848 does not match its reference from page (1:46982), slot 0.
Msg 8961, Level 16, State 1, Line 1
Table error: Object ID 373576369, index ID 1, partition ID 72057594081902592, alloc unit ID 72057594040549376 (type LOB data). The off-row data node at page (1:373412), slot 0, text ID 333774848 does not match its reference from page (1:46982), slot 0.
Msg 8961, Level 16, State 1, Line 1
Table error: Object ID 373576369, index ID 1, partition ID 72057594081902592, alloc unit ID 72057594040549376 (type LOB data). The off-row data node at page (1:373413), slot 0, text ID 333774848 does not match its reference from page (1:46982), slot 0.
Msg 8961, Level 16, State 1, Line 1
Table error: Object ID 373576369, index ID 1, partition ID 72057594081902592, alloc unit ID 72057594040549376 (type LOB data). The off-row data node at page (1:373414), slot 0, text ID 333774848 does not match its reference from page (1:46982), slot 0.
Msg 8961, Level 16, State 1, Line 1
Table error: Object ID 373576369, index ID 1, partition ID 72057594081902592, alloc unit ID 72057594040549376 (type LOB data). The off-row data node at page (1:373415), slot 0, text ID 333774848 does not match its reference from page (1:46982), slot 0.
Msg 8929, Level 16, State 1, Line 1
Object ID 373576369, index ID 1, partition ID 72057594081902592, alloc unit ID 72057594094747648 (type In-row data): Errors found in off-row data with ID 1311506432 owned by data record identified by RID = (1:2277271:5)
Msg 8929, Level 16, State 1, Line 1
Object ID 373576369, index ID 1, partition ID 72057594081902592, alloc unit ID 72057594094747648 (type In-row data): Errors found in off-row data with ID 333774848 owned by data record identified by RID = (1:2282679:0)
CHECKDB found 0 allocation errors and 10 consistency errors in table 'AllDocStreams' (object ID 373576369).
CHECKDB found 0 allocation errors and 10 consistency errors in database 'WSS_Content_CustomerDocs'.
repair_allow_data_loss is the minimum repair level for the errors found by DBCC CHECKDB (WSS_Content_CustomerDocs).
Seems fairly scary but I actually started to relax a little once I read this, for reasons that will become apparent.
The first thing to understand about this database is that it is a large sharepoint content database.
This is actually great news because it means that the *vast* majority of the data in the db is not actually *row* data, it’s going to be BLOB data that represents the various files in SharePoint. I say good because in a 100GB content database, sheer probability suggests that if we did get a small corruption it would very likely fall within the BLOB data of a single file rather than row data or the intrinsic data structures of SQL Server. Actual corruption to rows or intrinsic data structures are far more problematic and I’d gladly write off a word document or powerpoint presentation if it meant not having to deal with that 😉
Reading through the output we can see that SQL Server is having an issue reconciling the row data stored on a single 8K page with the binary LOB data it stores “off row”. This tells me the following:
- The root issue is with a single 8K page
- The broader issue with that 8K page is that some pointers to the “off row” data seems a bit messed up.
- Given the number of “off row” pages involved (8), the corruption seems to be very limited in scope – probably about 64KB given an 8K page size. It’s quite likely in fact that if we could pin it down, we might only be dealing with one or two corrupt files
In the grand scheme of things, this isn’t actually that bad.
Finding out what’s actually damaged
We now have a fairly good assessment of the scale of the corruption but we don’t actually have a great understanding of what that corruption corresponds to in the real world. Given that we’re talking about a SharePoint content database here that binary data could correspond to a system critical .aspx page or the sales guys sharing a humorous gif:

The key areas of the error message I’m now interested are the two lines near the end which say something along the lines of:
Errors found in off-row data with ID 1311506432 owned by data record identified by RID = (1:2277271:5)
We’re also told that the only errors were found in the AllDocStreams table.
The RID referenced above is crucial because if I could determine what actual row RID (1:2277271:5) corresponds to, I have a very good chance of determining what the real world file is.
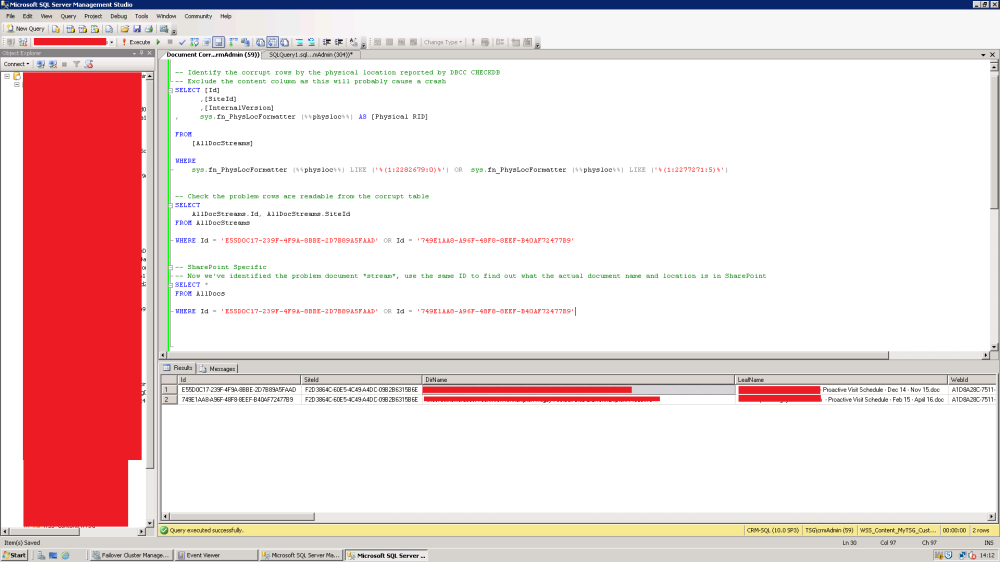
Using the undocumented sys.fn_PhysLocFormatter function we can do just that – take a low level RID and use it to identify the human readable row. The full (Sharepoint specific) query I used is as follows:
-- Identify the corrupt rows by the physical location reported by DBCC CHECKDB
-- Exclude the content column as this will probably cause a crash
SELECT [Id]
,[SiteId]
,[InternalVersion]
, sys.fn_PhysLocFormatter (%%physloc%%) AS [Physical RID]
FROM
[AllDocStreams]
WHERE
sys.fn_PhysLocFormatter (%%physloc%%) LIKE ('%(1:2282679:0)%') OR sys.fn_PhysLocFormatter (%%physloc%%) LIKE ('%(1:2277271:5)%')
The results returned 2 rows indicating that as expected, at most 2 document streams were involved.
We then did a query on the document IDs on sharepoint’s AllDocs table to get the actual locations and file names of the corrupt files.
-- Check the problem rows are readable from the corrupt table
SELECT
AllDocStreams.Id, AllDocStreams.SiteId
FROM AllDocStreams
WHERE Id = 'E55D0C17-239F-4F9A-8BBE-2D7B89A5FAAD' OR Id = '749E1AA8-A96F-48F8-8EEF-B40AF72477B9'
-- SharePoint Specific
-- Now we've identified the problem document *stream*, use the same ID to find out what the actual document name and location is in SharePoint
SELECT *
FROM AllDocs
WHERE Id = 'E55D0C17-239F-4F9A-8BBE-2D7B89A5FAAD' OR Id = '749E1AA8-A96F-48F8-8EEF-B40AF72477B9'
The results can be seen below. I’ve had to obscure some of it but you can hopefully make out that the two problem files are effectively 2 Word documents.
So – we’ve managed to confirm that our relatively scary corruption scenario is actually just a problem with 2 files.
The structure of the database is fine and there is no nasty low level row data involvement that would lead us to be worried about row inconsistencies if we tried a repair.
With the two document locations in hand I then went into SharePoint and attempted to open the document in question. Sure enough the documents were corrupt, but crucially SharePoint didn’t have any issues attempting to open them or download them. This was a very strong indicator that the corruption was contained entirely in the files themselves and that both SharePoint and the SQL Server itself were either oblivious or unconcerned with the corruption within.
OK – so this next bit was a bit of a gamble as there was no real guarantee over what would happen. It was better than the alternatives I had on offer though so was worth a whirl.
After checking that the documents were non-critical or could be retrieved from secondary sources I simply deleted the documents from Sharepoint. I figured there was a chance that SharePoint would crash at this point but I had a strong hunch that we would get away with it. My strong feeling at this point is that the corruption is solely in the payload of the documents, and even SQL Server is unaware of the corruption at a runtime level. It is actually when you ask it to go looking via a CHECK DB that it reports the problem.
I had to delete the documents from both the document libraries, site recycle bin and the site collection recycle bin but once that was done all seemed well. I ran another quick DBCC CHECKDB and it passed without issue.
Corruption begone!
Conclusion
I’ve got to be honest, the sort of corruption that we had was at the more benign end of the spectrum. No row data or internal data structures were actually involved in the corruption. We also got lucky that a straight delete of the data from SharePoint even worked.
That said, if there is a lesson to be learned from the episode it would be – “don’t overreact”.
Check what the actual corruption is using DBCC CHECKDB and think logically about what is likely to be damaged given the sort of data your storing.
If the system is still online (which it often will be) don’t feel compelled to act – take your time, gather information and you may well find that you can do a complete repair without a moments downtime